You Can’t See Me: Physical Removal Attacks on LiDAR-based Autonomous Vehicles Driving Frameworks

Physical Removal Attacks Overview
Autonomous Vehicles (AVs) use LiDAR-based object detection systems to perceive other vehicles and pedestrians on the road. Our team has discovered how to leverage laser-based spoofing techniques to selectively remove the LiDAR point cloud data of genuine obstacles at the LiDAR sensor level, before being used as input to the AV perception. The ablation of this critical LiDAR information causes autonomous vehicles to fail to identify and locate obstacles and, consequently, induces AVs to make dangerous automatic driving decisions. We call such attacks Physical Removal Attacks (PRA).
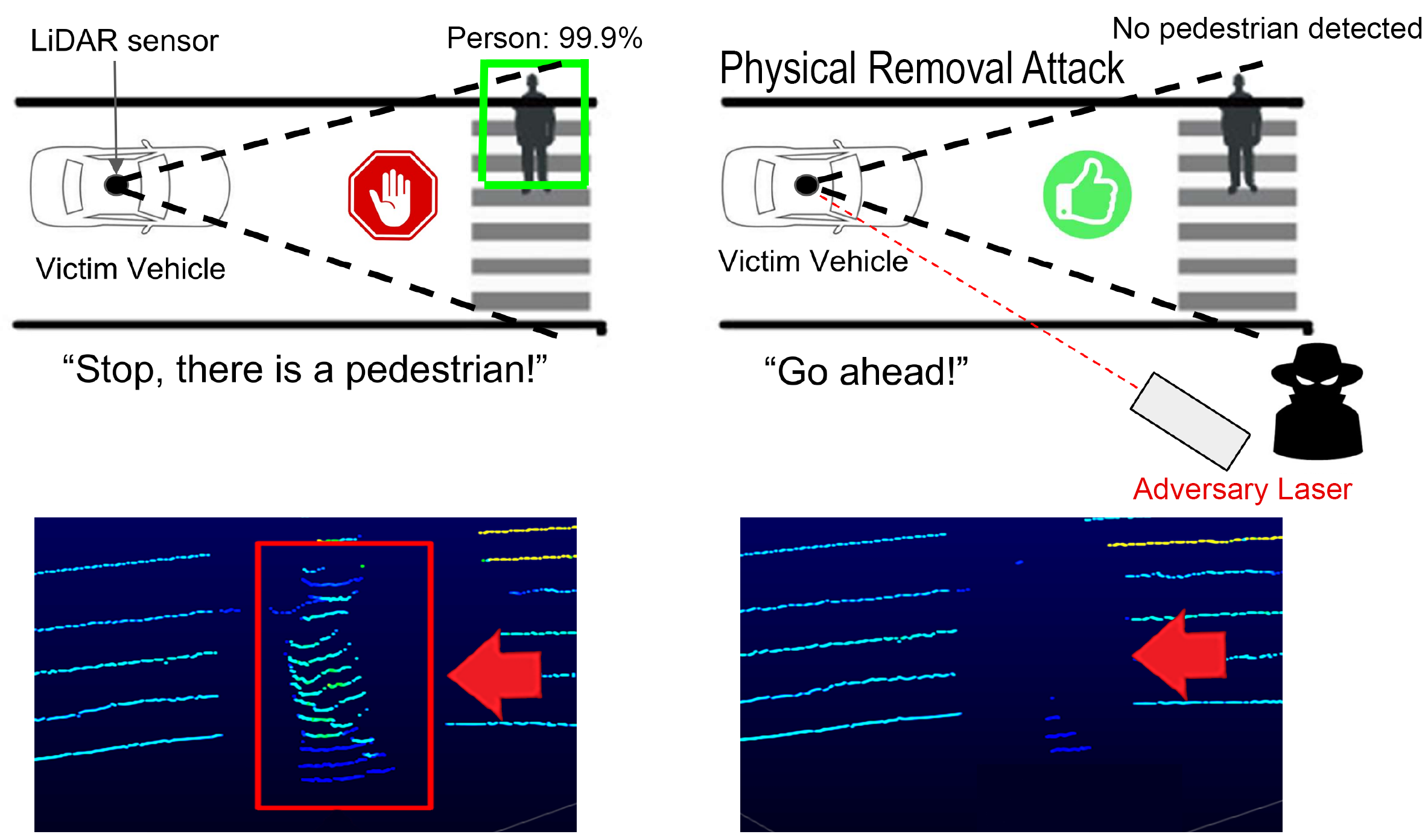
We demonstrate the attack's effectiveness against three popular AV obstacle detectors (Apollo, Autoware, PointPillars), and three fusion models (Frustum-ConvNet, AVOD, and Integrated-Semantic Level Fusion), reaching an attacker capability of 45 degree horizontal angle. In our moving vehicle scenarios, we achieve a 92.7% success rate removing 90% of a target obstacle’s cloud points. Finally, we propose two enhanced defense to mitigate the treath.
To appear in USENIX Security Symposium 2023
@inproceedings{cao2023youcantseeme,
title={You Can’t See Me: Physical Removal Attacks on LiDAR-based Autonomous Vehicles Driving Frameworks},
author={Yulong Cao and S. Hrushikesh Bhupathiraju and Pirouz Naghavi and Takeshi Sugawara and Z. Morley Mao and Sara Rampazzi},
booktitle={32nd {USENIX} Security Symposium ({USENIX} Security 23)},
year={2023}
}
Physical Removal Attacks Principles
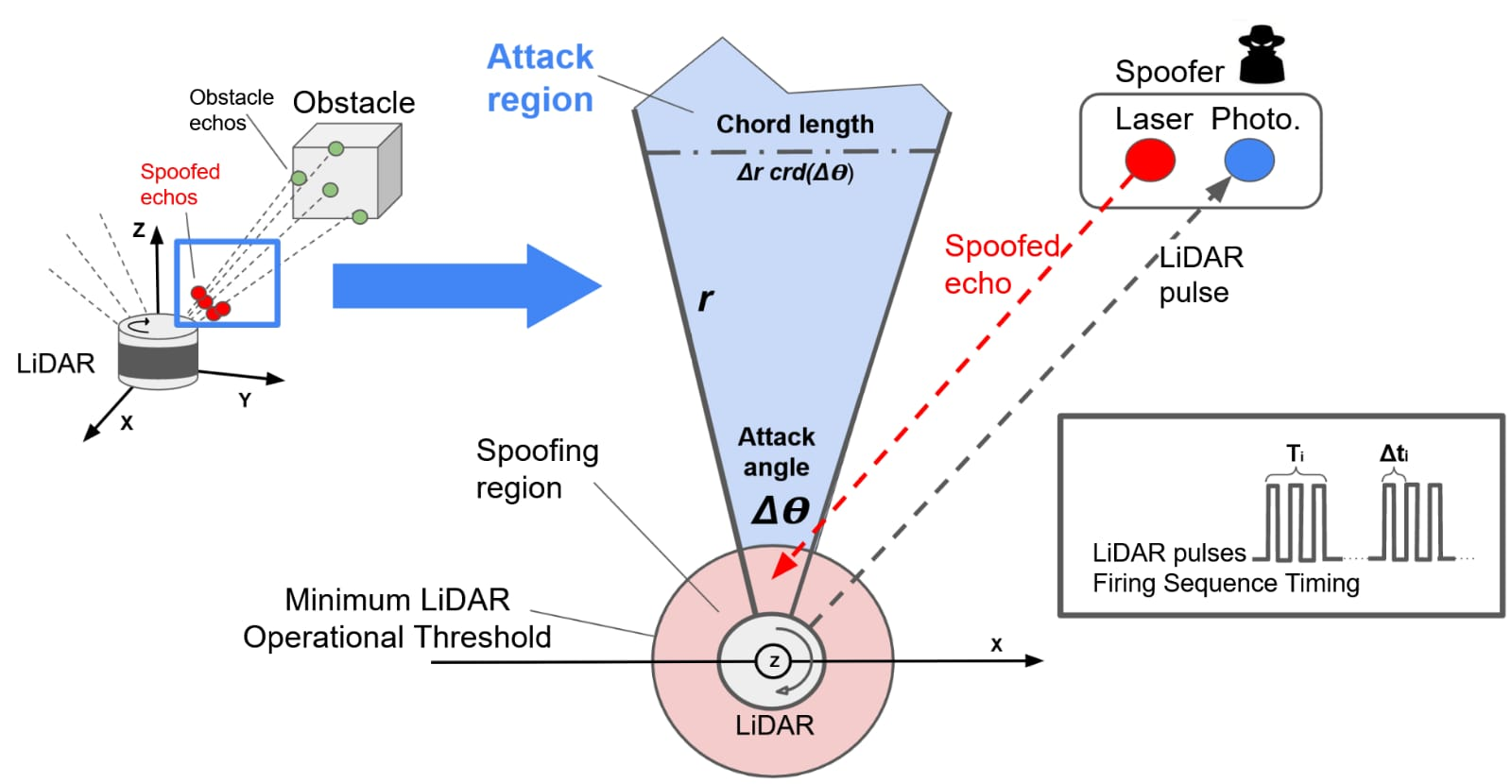
Our Physical Removal Attacks consist of injecting invisible laser signals in close proximity to the LiDAR sensor enclosure (namely, below the LiDAR operational threshold) to force the automatic discard of legitimate cloud points in the scene, such as the cloud points produced by genuine obstacles far away. The attack exploits a cascade effect in spinning LiDAR sensors integrated into AD frameworks, that rely on two main factors tied to the sensor functioning:
1) the intrinsic prioritization of the LiDAR sensors over strong reflections, and 2) the automatic filtering of the cloud points within a certain distance of the LiDAR sensor enclosure.

Removing the point cloud of a pedestrian
In this experiment, we evaluate our removal attack considering the following scenario: a pedestrian walking across in front of a stopped autonomous vehicle. The spoofer deployed 8 m away from the LiDAR on the side of the road aiming to remove the walking pedestrian in front of the vehicle with an horizontal attack angle of 8 degrees. The LiDAR is placed on top of the vehicle as in AV setting.
• AD Framework: Autoware.AI
• LiDAR model: VLP-16
• Point Cloud visualizer: Veloview
• Vehicle Information
○ Vehicle model: Jeep Cherokee 2018
○ Stationary vehicle (parking lot)
The following demo videos show the camera view and LiDAR point cloud.
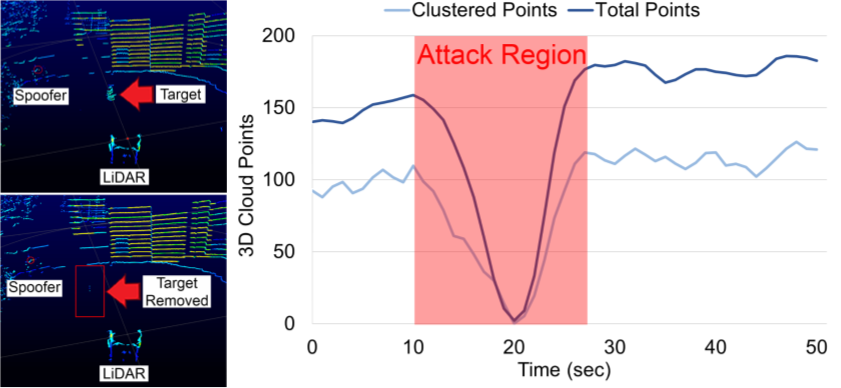
The image below shows how the obstacle point cloud is removed as a pedestrian walks through the attack region. The 3D point cloud (Left) with (bottom) and without (top) the attack. (Right) The decimation of the genuine cloud points during the attack. When the pedestrian walks in the attack region (10 seconds) and leave (27 seconds) (red area) the pedestrian object cloud points detected by the sensor and related cluster generated by Autoware are reduced to zero.
Attacking a moving vehicle
We conduct proof-of-concept PRA on moving vehicles with the LiDAR placed on top of a robot and a car. Though attacking moving vehicles introduces additional technical challenges, we demonstrate the feasibility of the attack by building a basic tracking system to track the LiDAR movements.
Moving Robot Scenario
In this demonstration, the LiDAR is located on top of a robot programmed to move toward a pedestrian, which is initially located 5m away from the robot, and back to its starting point. The spoofer is 5 m in front of the LiDAR as well, but it is shifted to one side to simulate the roadside attacker. The video below shows the LiDAR point cloud visualization on the right side and the camera recording of the attack on the left side. The point cloud traces of the experiment are available here (PCAP format).
• LiDAR model: VLP-16
• Vehicle Information
○ Robot model: Neato Botvac D85 Robot
○ The robot is moving 0.8 m forward and 0.8 m backward at full speed of 0.1 m/s
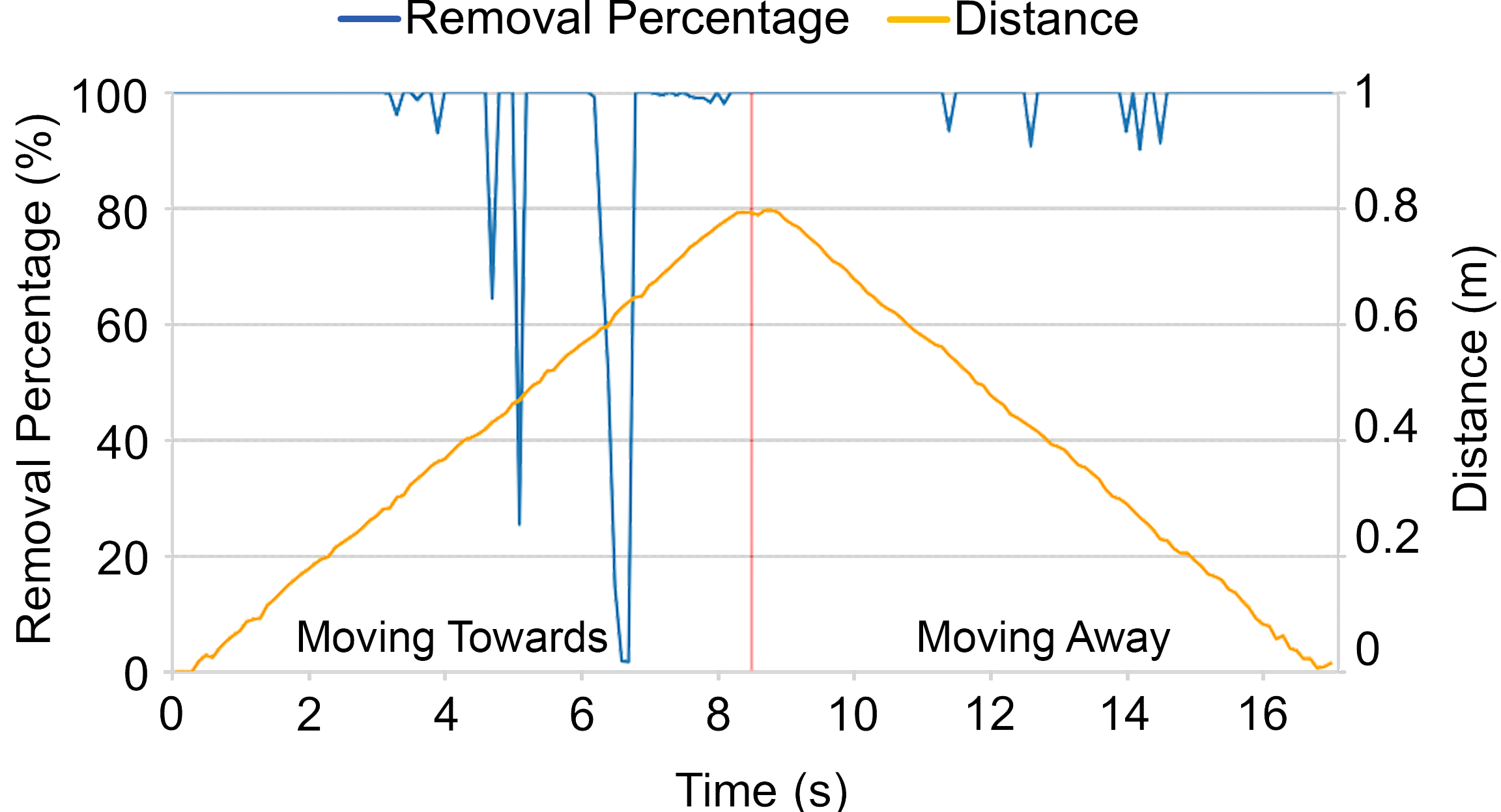
The experiment results shows a 95.9% success rate removing 90% of the target pedestrian cloud points, and 85.4% to completely remove all the cloud points.
Moving Car Scenario
This experiment aims to demonstrate the feasibility of attacking a moving AV. We drove a car towards the target obstacle to remove (a traffic cone). The car moves at a speed of 5 km/h with the cone obstacle distance ranging from 5 to 3 m away from the LiDAR sensor. The spoofer was positioned on the side of the car trajectory, behind the obstacle location.

The above video (left) shows the tracking systems camera view and the corresponding point cloud generated during the attack. The images (right) show the top-view location of the car and obstacle before and after the attack start.
Though it is more challenging to attack a moving car with variable speed, we demonstrate that PRA achieves 92.7% success rate for removing over 90% of the target traffic cone (83.6% success rate for removing all the cloud points). The point cloud traces of the experiment are available here (PCAP format).
End-to-End attack simulations
To demonstrate the consequences of the attack in AD settings, we perfomed our end-to-end evaluation on the LGSVL simulator, an open-source production-grade simulator designed for testing and development of AD frameworks.
To simulate PRA, we synthesize the sensor input changes corresponding to our attack on the input of the perception module in Baidu Apollo and direct the resulting output to the simulator to evaluate the AV control decisions in real-time.
For each scenario, we consider the victim's AV moving at constant acceleration from 0 to 32 km/h on a single-lane road.
The AV approaches two types of static obstacles (a car and a pedestrian) located in different positions along a crosswalk (e.g., along the AV's trajectory). We start simulating the attack when the AV's distance to the obstacle is 10, 20, 30, 40 and 50 meters, respectively.
• AD Framework: Baidu Apollo 5.0
• Baidu Apollo Planning Configuration.
• Simulator Platform LGSVL
• Simulation Scenarios
○ 2 attack angles - 5 and 10 degrees
○ 2 target obstacles - pedestrian and vehicle
○ 5 different obstacle positions
○ 5 different victim vehicle distances when attack starts - 10 m, 20 m, 30 m, 40 m, and 50 m
○ Map Single Lane Road
• AV information
○ AV model: Lincoln MKZ 2017
○ AV starts at 55 m from the obstacle (at 1 m left to the center of the road)
The video recordings of all the simulation scenarios are provided for additional reference. All the simulations start with the AV at 55 m away from the target obstacle. As an example, the following videos below show the simulations when the attack starts at 30 m from the obstacle positioned in the middle of the road with 5 degrees attack angle.
The simulation show that our removal attack, can lead to severe consequences and endanger the victim AV. Though the obstacle might be perceived again after the attack begins, we observe that the AV can still collide with the obstacle.
In the example above, the target pedestrian appears out of the attack region at 8 m from the AV, however, the AV collide with the pedestrian at 26 km/h as it is not able to timely stop. The target car appears out of the attack region at 17 m from the AV however, the AV collide with the vehicle at 16 km/h.
Speed variation
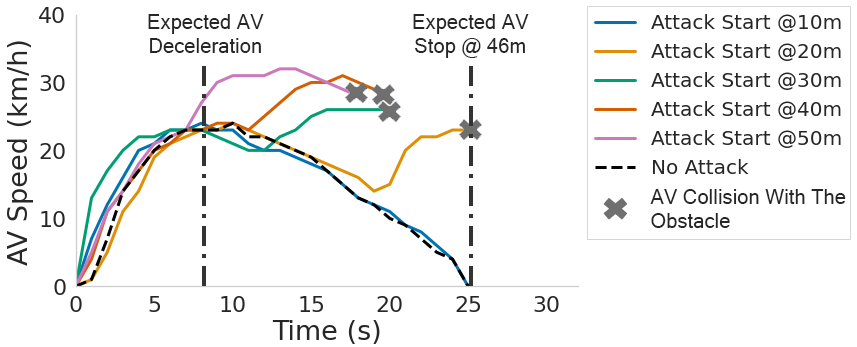
Without the attack, the victim AV is expected to accelerate to reach the preset speed (32 km/h) at 46 meters, then uniformly decelerate and stop before reaching the obstacle.
In the graphs below we observe the AV's speed change at different attack start conditions for 5 and 10-degree attack angles respectively. Figures (a) and (d) show that, by starting the attack at varying distances from the target obstacle, the attacker can remove the target obstacles for different time periods (based on the size of the obstacles and the attack angles). Figures (b), (c), (e), and (f), show that, though the obstacle is only removed in a limited amount of time, it will cause the AV to accelerate and collide with the obstacles. This is because when the attack starts and the target obstacle is removed, the victim AV will accelerate to reach the preset speed. The graphs also represent the expected AV stopping position in the scenario with no attack, and the position of the obstacle (marked as AV collision).
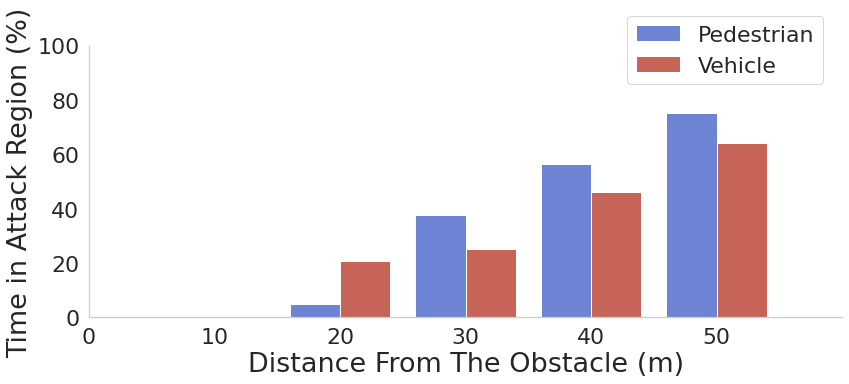

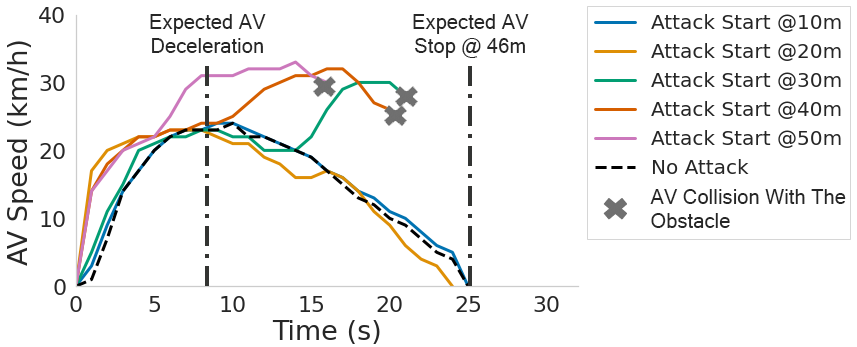
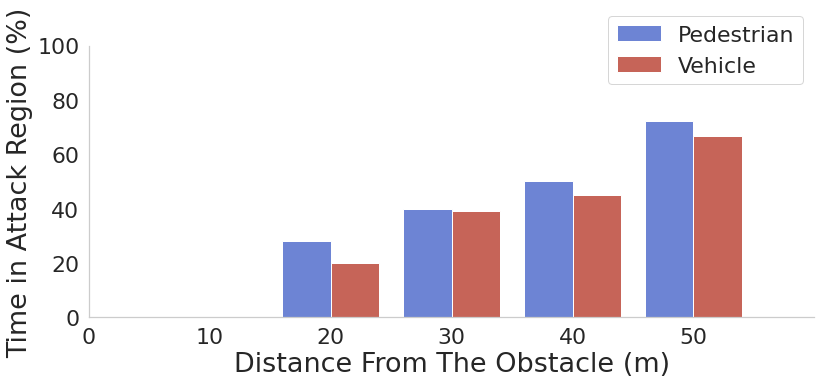
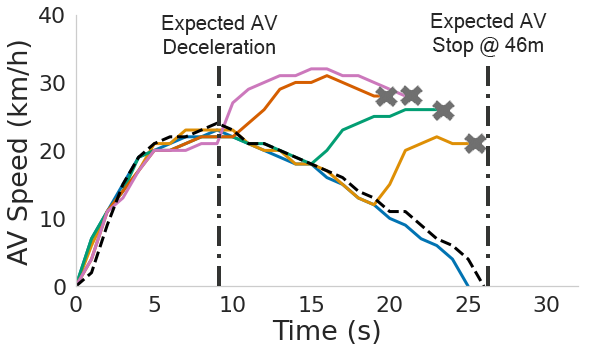
Impact on AV fusion models
Several AD framework rely on camera-LiDAR-based fusion models for object detection, object localization, and tracking. We demonstrate that PRA are robust against three state-of-the-art camera-LiDAR fusion models:
1) Frustum-ConvNet (FC): This Cascaded Semantic Level Fusion model takes the region proposals from the camera image and creates frustum level feature vectors from the LiDAR points. The model spatially fuses these frustum fea- tures to estimate an oriented 3D bounding box.
2) AVOD: This Feature Level Fusion extracts individual feature maps from the raw camera and LiDAR data and combines them.
3) Autoware Integrated-Semantic Level Fusion: This model fuses the feature outputs from independent detection stacks of camera and LiDAR sensors by back-projecting the detected object from the LiDAR onto the image space. Then it evaluates if there is at least a 50% overlap between the two detections to confirm an obstacle.
We use the detection rate as a metric to evaluate PRA. Our evaluation considers two analyses. In the first analysis (DEF), the intersection-over-union (IoU) evaluation is performed on the default thresholds for each model (0.7 for cars and 0.5 for pedestrians in the case of AVOD and Frustum-ConvNet, and a 50% overlap in Autoware Integrated-Semantic Level Fusion). In the second analysis (AVE), the evaluation is performed for all the possible IoU threshold values over 3D bounding box predictions for each fusion model (0.1 - 0.9 for Frustum-ConvNet and AVOD, 10% to 90% for Autoware). The resulting detection drop rates for increasing attack angle are shown below.
Angle |
||||||
Angle |
||||||
Acknowledgments
This research was funded by the JSPS KAKENHI Grant Number 22H00519, NSF under the National AI Institute for Edge Computing Leveraging Next Generation Wireless Networks, Grant Number 2112562, as well as NSF grant CNS-1930041, CMMI-2038215, and a gift from Facebook and Toyota. We thank the anonymous reviewers for the insightful comments, and Jennifer Sheldon for the help in proofreading.